Einleitung
1Die edition humboldt erscheint hybrid, aber mit einem „digital first“-Ansatz: alle edierten Texte und wissenschaftlichen Beiträge erscheinen zuallererst und unter einer offenen Lizenz in der edition humboldt digital.[1] Die edition humboldt digital folgt dabei einem „digitalen Paradigma“, wie es Patrick Sahle (2017) definiert hat: so ist die ehd nicht nur online einsehbar und basiert – im „single source“-Prinzip – auf TEI-XML, sondern verfügt auch über zahlreiche Informationen und Funktionen, die im Druck nicht verlustfrei umsetzbar sind.[1] Vgl. Kraft/Dumont 2020. Zum hybriden Konzept der Edition siehe auch Kraft 2018.
2Der vorliegende Beitrag möchte die grundlegende digitale Methodik der edition
humboldt digital vorstellen. Der Beitrag ist also im Kontext der geforderten
Transparenz editorischen Handels zu sehen (wie z.B. auch die Editionsrichtlinien
oder die jeweiligen Einführungen zu den edierten Texten). Er fokussiert aber auf
die genuin digitalen Aspekte der Edition, also auf das Datenmodell und die
Software, das Webdesign, nachgenutzte externe Daten und Dienste sowie die
Schnittstellen und Publikation der Daten. Der Beitrag versteht sich als ein
erster Überblick und wird inhaltlich durch weitere ergänzt.[2] An der Entwicklung der ehd waren und sind mehrere
Personen mit unterschiedlichen Verantwortlichkeiten beteiligt, die der Auflistung unter „Projektteam“![]() entnommen werden
können.[2] Zu nennen wären hier insbesondere die Editionsrichtlinien
entnommen werden
können.[2] Zu nennen wären hier insbesondere die Editionsrichtlinien![]() , Kraft
2018, Kraft/Dumont
2020 und Dumont et al.
2026.
, Kraft
2018, Kraft/Dumont
2020 und Dumont et al.
2026.
Datenmodell
3Dieser Abschnitt gibt einen Überblick über das Datenmodell der Edition. Die umfassende Dokumentation
des Datenmodells ist in den Editionsrichtlinien![]() einsehbar.[3][3] Zum Hintergrund des Datenmodells (z.B. dem Einsatz „kaskadierender
Standards“ oder den Editionsstufen) siehe auch Dumont et al. 2026.
einsehbar.[3][3] Zum Hintergrund des Datenmodells (z.B. dem Einsatz „kaskadierender
Standards“ oder den Editionsstufen) siehe auch Dumont et al. 2026.
Historische Quellen
Die Metadaten und Texte der zu edierenden Schriften (Reisetagebücher,
Dokumente und Briefe) werden nach den Richtlinien der Text Encoding Initiative
(TEI)![]() kodiert. Dabei wird durch Nutzung von ediarum.BASE.edit
weitgehend das Basisformat des Deutschen Textarchivs (DTABf)
kodiert. Dabei wird durch Nutzung von ediarum.BASE.edit
weitgehend das Basisformat des Deutschen Textarchivs (DTABf)![]() (Haaf/Geyken/Wiegand 2015)
verwendet, das u.a. im Rahmen dieses Editionsvorhabens für die Kodierung von
handschriftlichen Texten erweitert wurde (Haaf/Thomas 2018). Für einige
wenige projektspezifische Belange wurden Ergänzungen und Erweiterungen zum
Tagset vorgenommen, die konform zu den TEI-Richtlinien sind. Diese
Erweiterung betrifft insbesondere projektspezifische Anforderungen, die sich
durch das Material ergeben, wie z.B. die Auszeichnung von Maßangaben oder
eingelegte oder angeklebte Notizzettel. Bei den Erweiterungen gegenüber dem
DTABf-Datenmodell wurde aber darauf geachtet, dass diese möglichst nah an
dessen Systematik anschließen. So wurden in vielen Fällen keine neue
Elemente und Attribute, sondern nur Attributwerte ergänzt.
(Haaf/Geyken/Wiegand 2015)
verwendet, das u.a. im Rahmen dieses Editionsvorhabens für die Kodierung von
handschriftlichen Texten erweitert wurde (Haaf/Thomas 2018). Für einige
wenige projektspezifische Belange wurden Ergänzungen und Erweiterungen zum
Tagset vorgenommen, die konform zu den TEI-Richtlinien sind. Diese
Erweiterung betrifft insbesondere projektspezifische Anforderungen, die sich
durch das Material ergeben, wie z.B. die Auszeichnung von Maßangaben oder
eingelegte oder angeklebte Notizzettel. Bei den Erweiterungen gegenüber dem
DTABf-Datenmodell wurde aber darauf geachtet, dass diese möglichst nah an
dessen Systematik anschließen. So wurden in vielen Fällen keine neue
Elemente und Attribute, sondern nur Attributwerte ergänzt.
Alle Personen-, Orts- und Institutionsnamen sowie Literaturangaben in den Quellentexten (und ihren Metadaten) werden in den Texten mit ihrem jeweiligen Registereintrag verknüpft. Ebenfalls werden Datumangaben in den Tagebüchern kodiert und können darüber mit dem zeitlich nächsten Eintrag in der Chronologie automatisiert verknüpft werden.
Begleittexte
Alle weiteren Texte, wie z.B. die einführenden Forschungsbeiträge zum
Tagebuch-Fragment „Isle de
Cube. Antilles en général“![]() , wurden ebenfalls in TEI-XML gemäß dem
Basisformat des Deutschen Textarchivs erfasst.
, wurden ebenfalls in TEI-XML gemäß dem
Basisformat des Deutschen Textarchivs erfasst.
Register
Die Register zu Personen![]() , Orten
, Orten![]() und Institutionen
und Institutionen![]() sowie das Glossar
sowie das Glossar![]() werden in TEI-XML bearbeitet und vorgehalten. Jeder
Eintrag verfügt über eine eigene, eindeutige und permanente ID. Zusätzlich
zu den Basisdaten eines Eintrags wird außerdem eine Kurzbeschreibung
vorgehalten.
werden in TEI-XML bearbeitet und vorgehalten. Jeder
Eintrag verfügt über eine eigene, eindeutige und permanente ID. Zusätzlich
zu den Basisdaten eines Eintrags wird außerdem eine Kurzbeschreibung
vorgehalten.
8Die Einträge werden außerdem mit einer oder ggf. mehreren URIs aus
verschiedenen Normdateien versehen, sofern dort ein Eintrag existiert. Das
ermöglicht sowohl in der ehd selbst als auch bei Nutzung der Schnittstellen
und Datenpublikation eine projektübergreifende
Identifizierung der Personen, Orte und Instituionen (siehe zu Normdateien in
Editionen auch Stadler 2012).
Für Personeneinträge wird vornehmlich die GND, ersatzweise oder zusätzlich
auch Wikidata verwendet.Früher wurden auch VIAF benutzt,
dieses Vorgehen wurde aber aufgrund der Instabilitäten der VIAF-API und
ungewissen Zukunftsaussichten aufgegeben – Wikidata scheint hier
mittlerweile die bessere Alternative zu sein. Für Orte dagegen
werden dagegen URIs aus der freien Ortsdatenbank GeoNames![]() verwendet, da diese
weltweit eine hohe Abdeckung erzielt und Einträge bei Bedarf vom Vorhaben
selbst ergänzt werden können. So wurden einige wenige, in GeoNames fehlende,
Örtlichkeiten (wie die ehemaligen Standorte der Berliner Sternwarte
verwendet, da diese
weltweit eine hohe Abdeckung erzielt und Einträge bei Bedarf vom Vorhaben
selbst ergänzt werden können. So wurden einige wenige, in GeoNames fehlende,
Örtlichkeiten (wie die ehemaligen Standorte der Berliner Sternwarte![]() )
dort nachgetragen. [] Früher wurden auch VIAF benutzt,
dieses Vorgehen wurde aber aufgrund der Instabilitäten der VIAF-API und
ungewissen Zukunftsaussichten aufgegeben – Wikidata scheint hier
mittlerweile die bessere Alternative zu sein.
)
dort nachgetragen. [] Früher wurden auch VIAF benutzt,
dieses Vorgehen wurde aber aufgrund der Instabilitäten der VIAF-API und
ungewissen Zukunftsaussichten aufgegeben – Wikidata scheint hier
mittlerweile die bessere Alternative zu sein.
Darüber hinaus wurden im Rahmen des Projekts die Registerangaben von 25
zwischen 1973 und 2016 veröffentlichten Editionen (Briefe, Dokumente,
Tagebuch-Exzerpte) der Alexander von Humboldt-Forschung retrodigitalisiert
und zusätzlich bereitgestellt. Die Registerinformationen der gedruckten
Editionen sind Teil der zunächst im Akademie-Verlag und schließlich bei De
Gruyter veröffentlichten Reihe Beiträge zur Alexander von Humboldt-Forschung![]() ,
herausgegeben von der Alexander-von-Humboldt-Forschungsstelle (1970–2014)
der BBAW.
,
herausgegeben von der Alexander-von-Humboldt-Forschungsstelle (1970–2014)
der BBAW.
Verknüpfungen zu anderen Registereinträgen und den edierten Materialien werden anhand der ehd-ID automatisiert aus der Datenbank ausgelesen.
Humboldt'sche Verweissiglen
Auf Manuskripten von Alexander von Humboldt sind manchmal sog. Siglen zu finden, also Buchstabenkombinationen, die verschiedene Dokumente, Briefe und Tagebuchaufzeichnungen mit einander in Beziehung setzen. Diese Siglen wurden nicht nur transkribiert, sondern auch in einem eigenen TEI-XML-Register eingetragen und von den Textstellen dorthin verknüpft. So können die Beziehungen auch in der digitalen Edition nachverfolgt werden.
Pflanzenregister
Für das Pflanzenregister![]() werden keine eigenen Einträge in
TEI-XML-Registerdateien angelegt (wie bei den anderen Registern).
Stattdessen werden die wissenschaftlichen Pflanzennamen in den edierten
Texten mit Hilfe der entsprechenden TEI-Kodierung annotiert, ggf.
normalisiert und dann automatisch ausgelesen. Das Pflanzenregister wird
somit komplett dynamisch erstellt. Zu jedem distinkten Pflanzennamen
werden die Belegstellen in den Texten gelistet und automatisiert mit
verschiedenen taxonomischen Datenbanken verlinkt (siehe unten, Abschnitt
Globale Indizes für
wissenschaftliche Namen
werden keine eigenen Einträge in
TEI-XML-Registerdateien angelegt (wie bei den anderen Registern).
Stattdessen werden die wissenschaftlichen Pflanzennamen in den edierten
Texten mit Hilfe der entsprechenden TEI-Kodierung annotiert, ggf.
normalisiert und dann automatisch ausgelesen. Das Pflanzenregister wird
somit komplett dynamisch erstellt. Zu jedem distinkten Pflanzennamen
werden die Belegstellen in den Texten gelistet und automatisiert mit
verschiedenen taxonomischen Datenbanken verlinkt (siehe unten, Abschnitt
Globale Indizes für
wissenschaftliche Namen![]() ).
).
13Seit Version 10 (2024) wird das eigentlich dynamische Pflanzenregister allerdings zusätzlich automatisiert als TEI-XML erstellt (inkl. interne und externe Verweise). Dadurch kann das Pflanzenregister auch in Zukunft der Datenpublikation beigegeben werden.[4] [4] Siehe hierzu auch Abschnitt 3.2 in Dumont et al. 2026.
Zeichnungen und Skizzen
Seit der Version 9 gibt ein virtuelles „Register“ einen Überblick über Zeichnungen und Skizzen aus Humboldts oder anderer zeitgenössischer Hand in den edierten Texten. Es wird – ähnlich wie das Pflanzenregister – automatisiert aus den mit figure ausgezeichneten Abbildungen zusammengestellt.
Bibliographie
Die Bibliographie![]() der Edition wird in der
Literaturverwaltungssoftware Zotero gepflegt. Die öffentlich einsehbare
Zotero-Gruppe
der Edition wird in der
Literaturverwaltungssoftware Zotero gepflegt. Die öffentlich einsehbare
Zotero-Gruppe![]() ermöglicht die kollaborative Pflege der Daten
und kann von allen Interessierten abgerufen werden – auch in
verschiedenen Zitierstilen und Exportformaten (siehe unten).
ermöglicht die kollaborative Pflege der Daten
und kann von allen Interessierten abgerufen werden – auch in
verschiedenen Zitierstilen und Exportformaten (siehe unten).
Dokumentation
Die Dokumentation des Datenmodells erfolgt in DITA![]() , genauer gesagt in den DITA-Dateien von ediarum.BASE.manual
, genauer gesagt in den DITA-Dateien von ediarum.BASE.manual![]() . Dadurch werden Synergien genutzt sowie
Spezifizierungen oder Modifikationen gegenüber dem Datenmodell von
ediarum.BASE.edit dokumentiert. DITA (und nicht ODD) wurde gewählt, um diese
Kombination von ediarum.BASE.manual und Richtlinien
der edition humboldt digital
. Dadurch werden Synergien genutzt sowie
Spezifizierungen oder Modifikationen gegenüber dem Datenmodell von
ediarum.BASE.edit dokumentiert. DITA (und nicht ODD) wurde gewählt, um diese
Kombination von ediarum.BASE.manual und Richtlinien
der edition humboldt digital![]() zu ermöglichen. Darüber hinaus
beinhaltet die interne DITA-Dokumentation nicht nur die
Kodierungsrichtlinien anhand des konkreten Materials, sondern auch die
konkreten Bedienungsanweisungen in
ediarum.AVHR.edit.
zu ermöglichen. Darüber hinaus
beinhaltet die interne DITA-Dokumentation nicht nur die
Kodierungsrichtlinien anhand des konkreten Materials, sondern auch die
konkreten Bedienungsanweisungen in
ediarum.AVHR.edit.
Die Editionsrichtlinien verweisen jeweils auf die entsprechenden Teile der Dokumentation des DTABf.
Schema
Wurde das Schema anfangs in RelaxNG formuliert und gepflegt, liegt es
mittlerweile als TEI-ODD-Datei (Viglianti 2019) vor (aus der aber weiterhin RNG-Derivate
erstellt werden). Es wird mit Hilfe des ODD-Chaining vom ediarum.BASE.schema
abgeleitet, das wiederum vom DTABf ebgeleitet wird. Dadurch ist es möglich,
auf jeder Ebene (ediarum, edition humboldt digital)
die jeweiligen Änderungen zum nächst-"höheren" Schema zu pflegen und
nachzuvollzuziehen. Das Schema (sowohl TEI-ODD-Datei als auch RNG-Datei)
sind auf GitHub![]() veröffentlicht.
veröffentlicht.
Software & Technologien
Die Publikation edition humboldt digital wird von der
Erfassung bis hin zur Publikation in ediarum erstellt.
Die digitale Arbeitsumgebung ediarum![]() ist eine von der DH-Initiative TELOTA
ist eine von der DH-Initiative TELOTA![]() seit 2012
entwickelte Lösung, die es den Wissenschaftler:innen erlaubt, Transkriptionen
von Manuskripten, Kommentare und Registereinträge in TEI-konformem XML zu
bearbeiten, mit einem Text- und Sachapparat zu versehen und anschließend im Web
und als PDF zu veröffentlichen (Dumont/Fechner 2014). Dabei besteht ediarum
aus mehreren Softwaremodulen, die zur Erarbeitung einer digitalen Edition
entsprechend angepasst wurden. Zur Eingabe und Bearbeitung der Daten wird bei
der edition humboldt digital das Modul ediarum.BASE.edit
benutzt, das – wie es bei ediarum üblich ist – durch eine projektspezifisches
Modul ediarum.AVHR.edit ergänzt wird. Über das Modul
ediarum.REGISTER.edit werden die Registereinträge angelegt und gepflegt.
Ausnahme ist die Bibliographie, die in der Literaturverwaltungssoftware Zotero
gepflegt wird, dafür bietet ediarum.DB eine
entsprechende Schnittstelle zur Synchronisierung.
seit 2012
entwickelte Lösung, die es den Wissenschaftler:innen erlaubt, Transkriptionen
von Manuskripten, Kommentare und Registereinträge in TEI-konformem XML zu
bearbeiten, mit einem Text- und Sachapparat zu versehen und anschließend im Web
und als PDF zu veröffentlichen (Dumont/Fechner 2014). Dabei besteht ediarum
aus mehreren Softwaremodulen, die zur Erarbeitung einer digitalen Edition
entsprechend angepasst wurden. Zur Eingabe und Bearbeitung der Daten wird bei
der edition humboldt digital das Modul ediarum.BASE.edit
benutzt, das – wie es bei ediarum üblich ist – durch eine projektspezifisches
Modul ediarum.AVHR.edit ergänzt wird. Über das Modul
ediarum.REGISTER.edit werden die Registereinträge angelegt und gepflegt.
Ausnahme ist die Bibliographie, die in der Literaturverwaltungssoftware Zotero
gepflegt wird, dafür bietet ediarum.DB eine
entsprechende Schnittstelle zur Synchronisierung.
Die Speicherung der Daten erfolgt via ediarum.WEBDAV (Lampert et al. 2025) zuerst in einem
Git (Fechner/Klappenbach/Lampert
2025) und in einer zweiten Stufe (automatisiert) in einer Instanz der
freien XML-Datenbank existdb![]() , hier
wird auch das Modul ediarum.DB zur Verwaltung der Daten
genutzt. Existdb dient – zusammen mit dem Webserver Jetty – als Basis der
digitalen Edition, die mit XQuery, XSLT und XPath realisiert wurde und
mittlerweile in einer eXistdb-App gemäß den EXPath packaging specifications
vorgehalten wird, was Deployment und Entwicklung vereinfacht. Für die
Suchfunktionen wird die seit eXistdb 5.0 verfügbare, auf Lucene basierende
Facettierung genutzt. Darüber hinaus verfügt die Edition über mehrere eigens
programmierte Caches, die die Performance insbesondere bei aufwendigen Abfragen
erhöhen. Zur Anzeige der Faksimiles, Zeichnungen und Abbildungen wird die am MPI
für Wissenschaftsgeschichte entwickelte Software digilib
, hier
wird auch das Modul ediarum.DB zur Verwaltung der Daten
genutzt. Existdb dient – zusammen mit dem Webserver Jetty – als Basis der
digitalen Edition, die mit XQuery, XSLT und XPath realisiert wurde und
mittlerweile in einer eXistdb-App gemäß den EXPath packaging specifications
vorgehalten wird, was Deployment und Entwicklung vereinfacht. Für die
Suchfunktionen wird die seit eXistdb 5.0 verfügbare, auf Lucene basierende
Facettierung genutzt. Darüber hinaus verfügt die Edition über mehrere eigens
programmierte Caches, die die Performance insbesondere bei aufwendigen Abfragen
erhöhen. Zur Anzeige der Faksimiles, Zeichnungen und Abbildungen wird die am MPI
für Wissenschaftsgeschichte entwickelte Software digilib![]() eingesetzt.
eingesetzt.
Dieser Software-Stack wurde 2015 gewählt, weil er seit 2012 an der BBAW standardmäßig für neugermanistische Editionen zum Einsatz kommt. Existdb ist bereits seit den 2000ern im Haus im Einsatz, die auf Oxygen XML Author basierenden ediarum-Eingabemodule seit 2012. Dadurch kann für diese Softwares im Speziellen und die X-Technologien im Allgemeinen, auf umfangreiche Expertise im TELOTA-Team zurückgegriffen werden. Gerade auch ediarum (insbesondere das Modul ediarum.BASE) sollte es ermöglichen, Software projektübergreifend zu (weiterzu-)entwickeln, bereitszustellen und zu warten. Ediarum wurde zu Projektbeginn bereits in einigen Vorhaben erfolgreich eingesetzt, mittlerweile wird es in über 30 Editionsvorhaben – nicht nur an der BBAW – verwendet. Mit dem Einsatz von ediarum (und dem Technologiestack insgesamt) wird eine Insellösung vermieden und Synergieeffekte genutzt. So konnte das Editionsvorhaben auch auf die bereits vorhandenen ediarum-Entwicklungen aufbauen und profitiert(e) auch von neuen Funktionalitäten, die für ediarum in anderen Editionsvorhaben der BBAW entwickelt wurden – was natürlich auch umgekehrt gilt. Ebenso werden Fehlerbehebungen in ediarum für alle ediarum-Projekte gleichzeitig wirksam.
Allerdings konnte die edition humboldt digital nicht von allen ediarum-Neuentwicklungen profitieren. So kommt für die Schicht der Webpräsentation nicht das Modul ediarum.WEB zum Einsatz, da dieses erst einige Jahre später entwickelt wurde. Eine Umstellung bei Beihaltung aller Features war zu aufwändig. Die Verwendung vom TEI Publisher, der zu Beginn des Projekts schon in ersten Versionen erschienen war, schied aufgrund des damals recht begrenzen Funktionsumfang aus. Daher wurde die ehd maßgeschneidert in XQuery/XSLT realisiert. So gehört die ehd – wie viele andere auch – zu den „Haute couture“-Editionen, wie es Elena Pierazzo 2019 formulierte. Das ist auch deshalb möglich, weil das Vorhaben im Rahmen des Akademienprogramm für eine Förderung von 18 Jahren geplant ist. Abgesehen von dem Fehlen von „prêt-à-porter“-Lösungen zu Projektbeginn, erscheint aber eine „Haute couture“-Lösung für die ehd aber auch aufgrund des Umfangs und der Heterogenität der edierten Quellen sowie der begleitenden Informationen (Register, Chronologie, Forschungsbeiträge etc.) sinnvoll wenn nicht gar notwendig.
Gestaltung & Webdesign
Die Gestaltung der edition humboldt digital entstammt Entwürfen, die der Autor ursprünglich 2014 für das Vorhaben „Schleiermacher in Berlin 1808-1834“ entwickelte. Aufgrund der grundsätzlichen Ähnlichkeit des Editionstypus und der zu präsentierenden Quellengattungen, konnten die Entwürfe nachgenutzt und für die ehd weiterentwickelt werden.
Die Gestaltung lehnt sich an Prinzipien des „Flat Designs“ an, d.h. Schlichtheit, Minimalismus und ein starker Fokus auf Typographie. Gerade letzteres ist ein zentraler Punkt, geht es doch bei dieser digitalen Edition vor allem um eines: Text. Daher wurde sich auch für eine Antiqua (PT Serif) als Hauptschrift entschieden, die über einen echten kursiven Schnitt verfügt. Begleitet wird sie von einer Groteske (PT Sans) aus derselben Schriftsippe, die vor allem in Subnavigationen, kleiner gesetzt Hinweistexten und Metangaben zum Einsatz kommt. Diesen klassischen typographischen Konventionen, soweit sie sich sinnvoll aufs digitale Medium Web übertragen ließen, wurde auch bei der weiteren Gestaltung Rechnung getragen. So wurde beispielsweise auf eine flexible, sich an die Breite des Viewports orientierende Textbreite verzichtet - zugunsten einer festen, die in etwa mit der typographisch empfohlenen Zeilenlänge korrespondiert.
Der Gestaltungsansatz verzichtet auch bewusst auf einen Seitenheader: Um den Texten möglichst viel Platz einzuräumen, wurde nur eine niedrige, aber durch die schwarze Farbe gut sichtbare Navigationsleiste oben platziert. Den Seitenkopf nimmt anstelle von (2014 durchaus noch üblichen) Website-Titel und Trägerlogos der Dokumenttitel oder Titel der einzelnen Seite ein. Gleichzeitig bietet dieser Raum auch weiteren Metaangaben und Sub-Navigationen Platz (Chronologisches Blättern zw. den Briefen; Unterbereichsnavigation; Buchstaben im Register etc.).
26Zwei Herausforderungen hat die Gestaltung zu meistern: Zum einen die Fülle an unterschiedlichen Texttypen (edierte Briefe, Tagebücher, Dokumente; Forschungsbeiträge und Register) und Informationen, die untergebracht werden wollen. Hier verfolgt die Gestaltung ehd das Prinzip, nicht alles sofort zu zeigen, sondern bestimmte Informationen erst auf Nutzerinteraktion einzublenden. Stets soll genügend Weißraum bleiben, um das Auge auch mal ruhen zu lassen bzw. die unterschiedlichen Informationen sinnvoll gruppieren und priorisieren zu können. Eine zweite Herausforderung war (und ist) die Gestaltung an die sich ändernenden Anforderungen und stetig wachsende Material- und Informationsfülle anzupassen. Bei einem so lange laufenden Akademienvorhaben (2015–2032) war am Anfang längst noch nicht jeder Informationstyp und Funktion absehbar. So wurde auch die Gestaltung immer wieder angepasst - von der Einführung einer Subnavigation, über das Redesigns der Startseite und die Einführung der seitenbasierten Text- und Faksimiledarstellung bis hin zu den immer tiefer und komplexer ausgezeichneten edierten Texten. Das ist mal mehr, und sicherlich auch mal weniger gut gelungen.[5][5] Zumindest Christian von Zimmermann lobt im Hinblick auf die Gestaltung der Forschungsbeiträge: „[...] und eindrücklich widerlegt diese digitale Edition das häufig angeführte Vorurteil, es sei nicht möglich, lange Texte im digitalen Medium lesbar und übersichtlich zu präsentieren“ (Von Zimmermann 2024, 292).
Bei der Umsetzung des Designs in HTML wurde das 960
Grid System![]() eingesetzt und stark auf CSS gesetzt. Javascript wird
lediglich für spezielle – notfalls ersetzbare – Funktionen der Oberfläche
eingesetzt; die Generierung der HTML-Seiten erfolgt somit weitgehend
serverseitig, um eine Archivierung im Web Archive oder im Webarchiv der BBAW zu
erleichtern.
eingesetzt und stark auf CSS gesetzt. Javascript wird
lediglich für spezielle – notfalls ersetzbare – Funktionen der Oberfläche
eingesetzt; die Generierung der HTML-Seiten erfolgt somit weitgehend
serverseitig, um eine Archivierung im Web Archive oder im Webarchiv der BBAW zu
erleichtern.
Verwendete externe Daten & Webservices
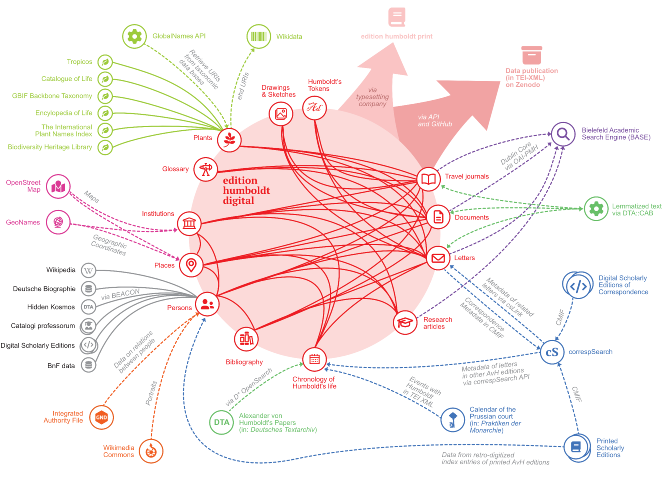 Die vernetzte edition humboldt digital. Gleichzeitig publiziert im
Poster "The networked edition humboldt digital". DH2023 in Graz. Abstract:
https://zenodo.org/record/8107834
Die vernetzte edition humboldt digital. Gleichzeitig publiziert im
Poster "The networked edition humboldt digital". DH2023 in Graz. Abstract:
https://zenodo.org/record/8107834Für die digitale Edition wurden an mehreren Stellen Daten aus Drittprojekten nachgenutzt bzw. externe Webservices verwendet.
Cascaded Analysis Broker des Deutschen Textarchiv (DTA::CAB)
Die normale Suche kann um eine Funktion erweitert werden, die auch
historische Schreibweisen und andere Wortformen findet. Zu diesem Zweck
werden die edierten Texte mit Hilfe des Webservices DTA::CAB![]() linguistisch analysiert und annotiert. Dabei werden u.a. auch alle Wörter
lemmatisiert, so dass auf Basis dieses Lemmas gesucht werden kann. DTA::CAB
wurde im Rahmen des Deutschen Textarchivs
linguistisch analysiert und annotiert. Dabei werden u.a. auch alle Wörter
lemmatisiert, so dass auf Basis dieses Lemmas gesucht werden kann. DTA::CAB
wurde im Rahmen des Deutschen Textarchivs![]() von Bryan Jurish entwickelt.
von Bryan Jurish entwickelt.
Für weitere Informationen siehe die Dokumentation![]() oder Jurish
2012.
oder Jurish
2012.
Humboldts Schriften im Deutschen Textarchiv
Im Deutschen Textarchiv sind über 180
Schriften Alexander von Humboldts![]() TEI-XML-kodiert im Volltext
verfügbar. In der Chronologie wurde eine Funktion implementiert, die die
Titeldaten dieser Schriften mit anzeigt bzw. durchsucht. Dafür wird die vom
Deutschen Textarchiv bereitgestellte D* OpenSearch API
TEI-XML-kodiert im Volltext
verfügbar. In der Chronologie wurde eine Funktion implementiert, die die
Titeldaten dieser Schriften mit anzeigt bzw. durchsucht. Dafür wird die vom
Deutschen Textarchiv bereitgestellte D* OpenSearch API![]() (dazu:OpenSearch
Description
(dazu:OpenSearch
Description![]() ) verwendet. So können die Volltexte von Humboldts
Schriften nicht nur angezeigt, sondern auch durchsucht werden: Die
Suchfunktion erlaubt es, die Anzahl der Treffer anzugeben und direkt auf die
Trefferliste zu verlinken.
) verwendet. So können die Volltexte von Humboldts
Schriften nicht nur angezeigt, sondern auch durchsucht werden: Die
Suchfunktion erlaubt es, die Anzahl der Treffer anzugeben und direkt auf die
Trefferliste zu verlinken.
Digitalisate-Bibliographie auf avhumboldt.de
Im Rahmen des Portals avhumboldt.de wird unter der Leitung von Tobias Kraft
seit 2009 eine Digitalisate-Bibliographie![]() der selbständig erschienenen Schriften
Alexander von Humboldts bereitgestellt. Die Daten dieser Bibliographie
wurden in XML konvertiert und in die Datenbank der edition humboldt digital integriert, um in der Chronologie
angezeigt werden zu können.
der selbständig erschienenen Schriften
Alexander von Humboldts bereitgestellt. Die Daten dieser Bibliographie
wurden in XML konvertiert und in die Datenbank der edition humboldt digital integriert, um in der Chronologie
angezeigt werden zu können.
correspSearch
Der Webservice correspSearch![]() aggregiert maschinenlesbare Briefverzeichnisse von gedruckten oder digitalen
Briefeditionen und macht sie zentral recherchierbar (Dumont et al 2025; Dumont 2023, Dumont 2018). Darüber hinaus
bietet er eine Schnittstelle
aggregiert maschinenlesbare Briefverzeichnisse von gedruckten oder digitalen
Briefeditionen und macht sie zentral recherchierbar (Dumont et al 2025; Dumont 2023, Dumont 2018). Darüber hinaus
bietet er eine Schnittstelle![]() an, die es ermöglicht, diese Daten auch
automatisiert abzufragen und in eigenen Programmen nachzunutzen. Da
Humboldts Korrespondenz (Schwarz
2018) schon in den 1960er Jahren als zu umfangreich angesehen
wurde, um sie in einer Gesamtausgabe zu edieren, wird sie seitdem in
einzelnen Briefwechselausgaben oder gar Aufsätzen (v.a. in der Zeitschrift
Humboldt im Netz
an, die es ermöglicht, diese Daten auch
automatisiert abzufragen und in eigenen Programmen nachzunutzen. Da
Humboldts Korrespondenz (Schwarz
2018) schon in den 1960er Jahren als zu umfangreich angesehen
wurde, um sie in einer Gesamtausgabe zu edieren, wird sie seitdem in
einzelnen Briefwechselausgaben oder gar Aufsätzen (v.a. in der Zeitschrift
Humboldt im Netz![]() )
verstreut veröffentlicht (Schröder
2008). In correspSearch sind erstmals fast alle über 7000 publizierten Briefe an und von Alexander von Humboldt
)
verstreut veröffentlicht (Schröder
2008). In correspSearch sind erstmals fast alle über 7000 publizierten Briefe an und von Alexander von Humboldt![]() zusammengeführt und für die Forschung recherchierbar gemacht.
zusammengeführt und für die Forschung recherchierbar gemacht.
In der edition humboldt digital werden diese Daten
über die API von correspSearch an zwei Stellen abgefragt: zum einen in der
Chronologie![]() (bei entsprechender Aktivierung dieser Option);
dadurch werden die über 1600 Einträge zu Humboldts Leben mit seiner
publizierten Korrespondenz zusammengebracht. Zum anderen wird die
correspSearch-API in der Einzelansicht eines Briefes unter „Briefnetz
erkunden“ angefragt. Dort werden Briefe von und an Alexander Humboldt aus
anderen Editionen abgefragt, um sichtbar zu machen, mit welchen anderen
Korrespondenzpartner:innen Humboldt im jeweiligen Zeitraum noch Kontakt
hatte. Darüber hinaus wird auch angezeigt, welche Briefe der jeweilige
Korrespondenzpartner:innen im entsprechenden Zeitraum empfangen und
versendet hat – die Abfrage erfolgt dabei anhand der im Register
hinterlegten GND- oder VIAF-URI. Auf diese Weise wird der „erweiterte
Korrespondenzkontext“ des Briefnetzes sichtbar gemacht (Dumont 2023). Diese Funktion
wurde ursprünglich in der edition humboldt digital
auf Basis von XQuery prototypisch entwickelt und danach im DFG-Projekt
correspSearch als frei nachnutzbares Javascript-Widget csLink
(bei entsprechender Aktivierung dieser Option);
dadurch werden die über 1600 Einträge zu Humboldts Leben mit seiner
publizierten Korrespondenz zusammengebracht. Zum anderen wird die
correspSearch-API in der Einzelansicht eines Briefes unter „Briefnetz
erkunden“ angefragt. Dort werden Briefe von und an Alexander Humboldt aus
anderen Editionen abgefragt, um sichtbar zu machen, mit welchen anderen
Korrespondenzpartner:innen Humboldt im jeweiligen Zeitraum noch Kontakt
hatte. Darüber hinaus wird auch angezeigt, welche Briefe der jeweilige
Korrespondenzpartner:innen im entsprechenden Zeitraum empfangen und
versendet hat – die Abfrage erfolgt dabei anhand der im Register
hinterlegten GND- oder VIAF-URI. Auf diese Weise wird der „erweiterte
Korrespondenzkontext“ des Briefnetzes sichtbar gemacht (Dumont 2023). Diese Funktion
wurde ursprünglich in der edition humboldt digital
auf Basis von XQuery prototypisch entwickelt und danach im DFG-Projekt
correspSearch als frei nachnutzbares Javascript-Widget csLink![]() neu umgesetzt (Müller-Laackman / Dumont 2022). Dieses kommt auch mittlerweile
in der ehd zum Einsatz.
neu umgesetzt (Müller-Laackman / Dumont 2022). Dieses kommt auch mittlerweile
in der ehd zum Einsatz.
Praktiken der Monarchie: Hofkalendarium
Ebenfalls in die Chronologie integriert sind Ereignisse am preußischen Hof, an denen Alexander von Humboldt
teilgenommen hat![]() und die im Hofkalendarium
und die im Hofkalendarium![]() ,
das Teil der Publikation „Praktiken der Monarchie“ ist, verzeichnet sind. Zu
diesem Zweck werden die TEI-XML-Daten des Hofkalendariums in die edition humboldt digital übernommen und die
Personenerwähnungen anhand der GND-URIs auf das ehd-Register gemappt (sofern
vorhanden, andernfalls verlinken sie auf die Registereinträge der Praktiken der Monarchie).
,
das Teil der Publikation „Praktiken der Monarchie“ ist, verzeichnet sind. Zu
diesem Zweck werden die TEI-XML-Daten des Hofkalendariums in die edition humboldt digital übernommen und die
Personenerwähnungen anhand der GND-URIs auf das ehd-Register gemappt (sofern
vorhanden, andernfalls verlinken sie auf die Registereinträge der Praktiken der Monarchie).
GeoNames & OpenStreetMap
Die im Register verzeichneten Orte und Institutionsstandorte sind in der
Regel mit einer URI der freien geographischen Datenbank GeoNames![]() versehen. So können die Orte projektübergreifend identifiziert werden, was
die Nachnutzung der Daten erheblich vereinfacht. Anhand der GeoNames-URI
werden auch die geographischen Koordinaten bezogen, auf deren Basis mit
Hilfe des freien Kartendienstes OpenStreetMap
versehen. So können die Orte projektübergreifend identifiziert werden, was
die Nachnutzung der Daten erheblich vereinfacht. Anhand der GeoNames-URI
werden auch die geographischen Koordinaten bezogen, auf deren Basis mit
Hilfe des freien Kartendienstes OpenStreetMap![]() eine entsprechende Karte bei den Orts- und
Institutionseinträgen angezeigt werden kann. Das ist insbesondere bei
kleineren Orten der verschiedenen Reisen Alexander von Humboldts
hilfreich.
eine entsprechende Karte bei den Orts- und
Institutionseinträgen angezeigt werden kann. Das ist insbesondere bei
kleineren Orten der verschiedenen Reisen Alexander von Humboldts
hilfreich.
Mit der Version 11 der edition humboldt digital wurden die geodatenbasierten
Funktionen im Ortsregister erweitert: Eine interaktive Weltkarte![]() gibt nun einen Überblick über alle Orte,
die im Ortsregister verzeichnet sind. Außerdem werden zu einem einzelnen Ort
in seinem Registereintrag benachbarte Orte, die ebenfalls im Register
aufgeführt werden, in einem Umkreis von ca. 30 km angezeigt - sowohl in der
Karte als auch als Liste mit Entfernungsangaben (Beispiel: Zmeëvka
gibt nun einen Überblick über alle Orte,
die im Ortsregister verzeichnet sind. Außerdem werden zu einem einzelnen Ort
in seinem Registereintrag benachbarte Orte, die ebenfalls im Register
aufgeführt werden, in einem Umkreis von ca. 30 km angezeigt - sowohl in der
Karte als auch als Liste mit Entfernungsangaben (Beispiel: Zmeëvka![]() ).
).
Gemeinsame Normdatei & BEACON
Anhand der in einem Eintrag des Personenregisters notierten URI aus der Gemeinsamen Normdatei![]() (GND) können weitere
Daten über den GND-Webservice „Entity Facts“ bezogen werden. So werden mit
Hilfe der „Entity Facts“ zum einen die Porträts direkt von Wikimedia Commons
eingeblendet; seit Version 12 (2026) werden die Porträts in einer Galerie
(GND) können weitere
Daten über den GND-Webservice „Entity Facts“ bezogen werden. So werden mit
Hilfe der „Entity Facts“ zum einen die Porträts direkt von Wikimedia Commons
eingeblendet; seit Version 12 (2026) werden die Porträts in einer Galerie![]() auch als ein weiterer Zugang zum
Personenregister genutzt. Zum anderen werden aus der GND Informationen zu
(familiären, freundschaftlichen etc.) Beziehungen zwischen Personen bezogen.
Diese werden anhand der GND-URIs auch in der ehd automatisiert ausgewertet.
Mit ihrer Hilfe werden den Benutzer:innen so automatisiert Beziehungen
zwischen im Register enthaltenen Personen angezeigt (siehe z.B. den Eintrag zu Samuel Thomas
Soemmerring
auch als ein weiterer Zugang zum
Personenregister genutzt. Zum anderen werden aus der GND Informationen zu
(familiären, freundschaftlichen etc.) Beziehungen zwischen Personen bezogen.
Diese werden anhand der GND-URIs auch in der ehd automatisiert ausgewertet.
Mit ihrer Hilfe werden den Benutzer:innen so automatisiert Beziehungen
zwischen im Register enthaltenen Personen angezeigt (siehe z.B. den Eintrag zu Samuel Thomas
Soemmerring![]() ).
).
Die GND-ID erlaubt es darüber hinaus, weitere Editionen, Lexika und Projekte
zu verlinken, die im Themenbereich der edition humboldt
digital relevant sind. Hierfür werden die BEACON-Schnittstellen
dieser Projekte genutzt. So ist es etwa möglich, thematische
Überschneidungen mit anderen Projekten des Zentrums Preußen-Berlin an der
BBAW![]() über die Verbindungen in den Registerdaten zu identifizieren
und der Forschung bereitzustellen (Beispiel Wilhelm von Humboldt
über die Verbindungen in den Registerdaten zu identifizieren
und der Forschung bereitzustellen (Beispiel Wilhelm von Humboldt![]() oder Friedrich
Schleiermacher
oder Friedrich
Schleiermacher![]() ). Aber auch externe Angebote, wie z.B. Hidden Kosmos
). Aber auch externe Angebote, wie z.B. Hidden Kosmos![]() oder Die deutsche
Biographie
oder Die deutsche
Biographie![]() werden so automatisiert verlinkt.
werden so automatisiert verlinkt.
40Das Retrieving von GND- und BEACON-Dateien sowie die darauf basierenden
Funktionen (Portraits, Verlinkungen etc.) werden seit 2025 nicht mehr
ausschließlich in der ehd-App umgesetzt, sondern schrittweise durch die
Nutzung von entityHub abgelöst. Der Webservice
entityHub wird derzeit als zentraler Service zur BEACON- und
Normdaten-Aggregation an der BBAW entwickelt (Dumont/Grabsch/Neuber 2026).[6] Ein Ziel von entityHub ist es, diese Daten
und Funktionen, die in vielen digitalen Editionen der BBAW verwendet werden,
zentral bereitzustellen, um die Entwicklung zu bündeln und die Wartung
dadurch erheblich zu vereinfachen.[6] Vgl. auch die Projektseite![]() .
.
Globale Indizes für wissenschaftliche Namen
Im Pflanzenregister (siehe
oben![]() ) werden verschiedene Webservices und APIs benutzt, um
wissenschaftliche Pflanzennamen aus Texten der edition
humboldt digital automatisiert mit passenden Einträgen aus
taxonomischen Datenbanken zu verknüpfen. Mithilfe des Webservices Global Names Resolver
) werden verschiedene Webservices und APIs benutzt, um
wissenschaftliche Pflanzennamen aus Texten der edition
humboldt digital automatisiert mit passenden Einträgen aus
taxonomischen Datenbanken zu verknüpfen. Mithilfe des Webservices Global Names Resolver![]() verlinkt das Pflanzenregister wissenschaftliche Namen mit Einträgen in der
Encylopedia of Life
verlinkt das Pflanzenregister wissenschaftliche Namen mit Einträgen in der
Encylopedia of Life![]() , Tropicos - Missouri Botanical
Garden
, Tropicos - Missouri Botanical
Garden![]() , The International
Plant Names Index
, The International
Plant Names Index![]() (IPNI). Darüber hinaus werden der Catalogue of Life
(IPNI). Darüber hinaus werden der Catalogue of Life![]() , die
Biodiversity Heritage
Library
, die
Biodiversity Heritage
Library![]() und die Global
Biodiversity Information Facility
und die Global
Biodiversity Information Facility![]() anhand ihrer eigenen
Schnittstellen abgefragt und ebenfalls verknüpft. Weitere Datenbanken
können, sofern sie über entsprechende technische Schnittstellen verfügen, in
Zukunft ergänzt werden.
anhand ihrer eigenen
Schnittstellen abgefragt und ebenfalls verknüpft. Weitere Datenbanken
können, sofern sie über entsprechende technische Schnittstellen verfügen, in
Zukunft ergänzt werden.
Die Abfrage der verschiedenen Datenbanken und automatisierte Verlinkung erfolgt dabei auf Basis des wissenschaftlichen Pflanzennamens, der im edierten Text entsprechend kodiert und ggf. normalisiert wird.
DeepL
Beginnend mit der Version 12 (2026) werden erste Teile der edition humboldt
digital vor der Publikation automatisiert ins Englische übersetzt. Im Moment
betrifft das nur die Chronologieeinträge, da sie als vollständige, kurze und
in modernem Deutsch verfasste Fließtexte sich am besten dafür eignen. Zu
diesem Zweck werden die einzelnen Einträge als XML über ein Skript an die
DeepL-API![]() geschickt und das Ergebnis gespeichert. Bei der
Übersetzung erhält DeepL die TEI-XML-Struktur der Snippets, so dass alle
Auszeichnungen (etwa von Personen und Orten) ebenfalls auch in der
englischen Version vorhanden sind. Zur Anwendung kommen bei Nutzung der
DeepL-API auch ein Glossar und Style Rules.
geschickt und das Ergebnis gespeichert. Bei der
Übersetzung erhält DeepL die TEI-XML-Struktur der Snippets, so dass alle
Auszeichnungen (etwa von Personen und Orten) ebenfalls auch in der
englischen Version vorhanden sind. Zur Anwendung kommen bei Nutzung der
DeepL-API auch ein Glossar und Style Rules.
Die so automatisiert übersetzten Beiträge werden in in der Anzeige mit einem entsprechendem Hinweis versehen. Es ist geplant, in Zukunft weitere Teile der Edition so übersetzen zu lassen. Erste Tests mit edierten Briefen zeigten gute Ergebnisse, schwieriger wird es bei Texten, die stärker fragementiert sind, wie die Reisetagebücher und Dokumente. Die automatische Übersetzung von edierten Texten birgt natürlich einerseits Risiken, würde aber andererseits den ersten Zugang zu den Texten für die stark internationalisierte Humboldt-Forschung deutlich erleichtern.
Die derzeit in Einzelfällen schon vorhandenen Übersetzungen edierter Texte sind aber allesamt redaktionell und editorisch bearbeitet und überprüft worden.
Besondere Funktionen
Visualisierungen in der Chronologie
Seit Version 12 (2026) bietet die Alexander von Humboldt-Chronologie drei Visualisierungen an. Zum einen wird auf der Einstiegsseite eine sog. „Heatmap“ angezeigt, die die Verteilung der über 1600 Chronologieeinträge darstellt. So können Benutzer:innen besser einschätzen, welche Zeitabschnitte die Chronologie wie gut abgedeckt. Wird ein einzelnes Jahr ausgewählt, wechselt die Heatmap zu einem Balkendiagramm, dass die Anzahl der Einträge pro Kalenderwoche anzeigt.
47Zum anderen bietet die Chronologie nun für eine Auswahl von Humboldts Reisen einen chronologisch-topografischen Zugang, in Form einer Karte, auf der die Reisestationen eingetragen sind. Auf der linken Seite ist die Reise mit Datum- und Ortsangaben[7] zusätzlich aufgelistet, rechts wird anhand der ausgewählten Station der entsprechende Chronologieeintrag angezeigt. Darunter werden diejenigen Seiten aus edierten Reisetagebüchern und Briefen in der ehd verlinkt, auf denen im TEI-XML das Datum des Tages von den Bearbeiter:innen ausgezeichnet wurde.[8] Dadurch wird erstmals ein systematischer Zugriff auf die Reisetagebücher anhand Humboldts Reiseroute möglich. [7] Als Ortsnamen werden – im Gegensatz zum Registereintrag – die zeitgenössischen Namen angezeigt.[8] In einigen Fällen wird das Datum auch in mehreren Reisetagebüchern erwähnt, nicht nur in Humboldts eigenem, sondern auch in denen seiner Reisegefährten.
48Optional können Nutzer:innen zusätzlich zur Reiseroute auch historische, oftmals zeitgenössische Karten[9] einblenden. Diese Karten sind mit Hilfe eines GIS-Programms über mehrere Punkte georeferenziert worden, so dass sie sich grundsätzlich an der richtigen Stelle der modernen Karte befinden. Aufgrund der historisch bedingten Ungenauigkeit dies zeitgenössischen Karten kann es jedoch zu kleineren Abweichungen kommen. Demgegenüber enthalten die historischen Karten aber zeitgenössische Informationen (Namen etc.), die sich in der modernen Karte, die von Open Street Map bezogen wird, nicht wiederfinden.[9] Im Fall der Uralkarte aus dem Jahr 1837 handelt es sich sogar um eine Karte, die u.a. mit Hilfe der Messungen von A. v. Humboldt angefertigt worden war und dem Bericht seines Reisebegleiters Gustav Rose beigegeben wurde.
Stellenkommentare wiederverwenden
Im Projektverlauf stellte sich heraus, dass für die Editor:innen nützlich wäre, einen Stellenkommentar wiederverwenden zu können. Dadurch könnten Sachverhalte zentral erläutert, aber auch an weiteren anderen Textstellen eingebunden werden. In der TEI-XML-Kodierung wird zu diesem Zweck der Stellenkommentar wie gewohnt einmalig angelegt. An allen weiteren Stellen kann durch eine entsprechende Auszeichnung einfach auf diesen Kommentar verwiesen werden. In der Weboberfläche der ehd wird an allen verknüpften Stellen der Kommentar entsprechend angezeigt. Zusätzlich listen solche wiederverwendeten Erläuterungen aber auf, auf welchen Seiten sie ebenfalls nachgenutzt wurden. Dadurch wird der Stellenkommentar weiter entlastet – auch über die mittlerweile übliche Verknüpfung von Namen, Werktiteln oder Glossarbegriffen hinaus.
Datenbereitstellung & APIs
Die Daten der edition humboldt digital können über verschiedene Schnittstellen sowie als kompletter TEI-XML-Datensatz bezogen werden. Darüber hinaus stehen verschiedene Schnittstellen zur Verfügung, mit denen andere Editionen oder Portale die ehd verlinken können. Dieser Abschnitt informiert darüber. Weitergehende Ausführungen zu diesem Thema können dem Aufsatz „Data on the Move“, der im Journal of the Text Encoding Initiative erschienen ist (Dumont et al. 2026), entnommen werden.
Lizenzierung
Die edition humboldt digital nutzt nicht nur externe
Daten und Webservices nach, sondern stellt ihre Daten auch wiederum unter
der freien Creative Commons-Lizenz CC BY-SA 4.0![]() über eine Schnittstelle und
als eigenständige Datenpublikation
über eine Schnittstelle und
als eigenständige Datenpublikation![]() zur Verfügung.
zur Verfügung.
TEI-XML-Schnittstelle
Alle edierten Texte, Forschungsbeiträge und Chronologie- und Registereinrräge
der edition humboldt digital können über die
TEI-XML-Schnittstelle http://edition-humboldt.de/api/v1.2/tei-xml.xql![]() (man beachte die
Version 1.2) abgerufen werden.
(man beachte die
Version 1.2) abgerufen werden.
Beim Aufruf ohne die Parameter wird eine Liste aller Daten mit Titel und Permalink der jeweiligen aktuellen Version angeboten. Beim Abruf mit Parameter type wird eine Liste der jeweiligen Dokumenttypen erzeugt (siehe nachstehende Tabelle). Beim Abruf mit Parameter id wird das jeweilige Dokument ausgegeben.
Parameter type
| Werte | Beschreibung |
|---|---|
| [nicht gesetzt] | alles, d.h. alle edierten Texte, Forschungsbeiträge, Chronologieeinträge sowie Einträge der Personen-, Institutionen-, Ortsregister und des Glossar |
| journals | alle Reisetagebücher |
| letters | alle Briefe |
| documents | alle „Dokumente“, d.h. edierte Texte, die nicht Reisetagebücher oder Briefe sind |
| articles | alle Forschungsbeiträge |
| chronology | alle Chronologieeinträge |
| people | alle Einträge des Personenregisters |
| institutions | alle Einträge des Institutionenregisters |
| places | alle Einträge des Ortsregisters |
| sigles | alle Humboldt'schen Verweissiglen |
| masses | alle Maßeinheiten |
| about | alle Informationstexte über diese Edition |
Datenpublikation
Alle edierten Texte, Forschungsbeiträge sowie das Personen-, Orts-, Institutionen- und Siglenregister werden auch als Gesamt-TEI-XML-Datensatz der edition humboldt digital veröffentlicht. Dazu werden die Texte und Einträge nicht einfach aus der eXistdb exportiert, sondern mit Hilfe eines XQuery-Skriptes über die TEI-XML-API 2.0 der ehd abgerufen, damit das Datenbild mit dem der über die API zugänglichen Daten übereinstimmt. Dadurch die dort stattfindenden Anreicherungen (z.B. GNDs; URIs statt IDs), die Harmonisierungen ans DTABf sowie die Aufteilung der Registerlisten in einzelne TEI-XML-Dateien genutzt. Dabei wird auch die Verzeichnisstruktur so geändert, dass die Daten nach Typ (d.h. Briefe, Tagebücher, Forschungsbeiträge, Registereinträge etc.) gegliedert vorliegen.
Zur ersten rein technischen Versionierung werden die so abgerufenen
TEI-XML-Dateien in ein Git-Repositorium gespielt, das auch öffentlich
einsehbar auf GitHub zur Verfügung steht![]() . Nach einer Überprüfung
und Ergänzung mit dem TEI-XML-Schema der ehd (als RNG) wird der Datensatz
von dort nach Zenodo exportiert, um dort langzeitarchiviert zur freien
Verfügung zu stehen: https://doi.org/10.5281/zenodo.13752841
. Nach einer Überprüfung
und Ergänzung mit dem TEI-XML-Schema der ehd (als RNG) wird der Datensatz
von dort nach Zenodo exportiert, um dort langzeitarchiviert zur freien
Verfügung zu stehen: https://doi.org/10.5281/zenodo.13752841![]() (kanonische URL, verlinkt
stets zur aktuellsten publizierten Version).
(kanonische URL, verlinkt
stets zur aktuellsten publizierten Version).
Weitere APIs
OAI-PMH
Die Metadaten der edierten Texte sowie der Forschungsbeiträge werden über
die Schnittstelle https://edition-humboldt.de/api/v1.1/oai-pmh.xql?verb=Identify![]() gemäß dem Protocoll for
Metadata Harvesting der Open Archive Initiative
gemäß dem Protocoll for
Metadata Harvesting der Open Archive Initiative![]() bereitgestellt. Dadurch werden diese Texte auch automatisch in der Bielefeld Academic Search
Enginge (BASE)
bereitgestellt. Dadurch werden diese Texte auch automatisch in der Bielefeld Academic Search
Enginge (BASE)![]() nachgewiesen. Als Metadatenformat für OAI-PMH
wird derzeit nur Dublin Core unterstützt.
nachgewiesen. Als Metadatenformat für OAI-PMH
wird derzeit nur Dublin Core unterstützt.
CMIF-Schnittstelle
Über diese Schnittstelle können die Korrspondenzmetadaten aller in dieser
Edition vorhandenen Briefe im Correspondence Metadata Interchange Format (CMIF)![]() abgerufen
werden. Dadurch werden die in dieser Edition edierten Briefe in
correspSearch nachgewiesen.
abgerufen
werden. Dadurch werden die in dieser Edition edierten Briefe in
correspSearch nachgewiesen.
Die Schnittstelle unterstützt auch schon einige Erweiterungen von CMIF v2![]() . So werden die erwähnten
Personen sowie die URL zum jeweiligen TEI-XML-Volltext ausgegeben.
Letzteres ermöglicht es, dass auch in correspSearch diese Briefe im
Volltext durchsucht und gefunden werden können (Beispiel:
“fieber*”
. So werden die erwähnten
Personen sowie die URL zum jeweiligen TEI-XML-Volltext ausgegeben.
Letzteres ermöglicht es, dass auch in correspSearch diese Briefe im
Volltext durchsucht und gefunden werden können (Beispiel:
“fieber*”![]() ).
).
URL: http://edition-humboldt.de/api/v1.2/cmif.xql![]()
BEACON-Dateien
Die im ehd-Datenbestand vorhandenen und mit der GND![]() -URI ausgezeichneten Personen können via http://edition-humboldt.de/api/v1.2/beacon.xql
-URI ausgezeichneten Personen können via http://edition-humboldt.de/api/v1.2/beacon.xql![]() als Liste im
BEACON-Format
als Liste im
BEACON-Format![]() abgerufen und darüber in externen digitalen
Angeboten automatisch verlinkt werden. Es ist dabei möglich, die Liste
auf Personen zu beschränken, die im Brieftext erwähnt werden oder die
Korrespondenzpartner sind (siehe nachfolgende Tabelle).
abgerufen und darüber in externen digitalen
Angeboten automatisch verlinkt werden. Es ist dabei möglich, die Liste
auf Personen zu beschränken, die im Brieftext erwähnt werden oder die
Korrespondenzpartner sind (siehe nachfolgende Tabelle).
Parameter
type
| Werte | Beschreibung |
|---|---|
| [nicht gesetzt] | alle Datensätze im Personenregister; standardmäßig gesetzt, sofern nicht anders angegeben |
| correspondents | alle Korrespondenzpartner |
| personMentioned | alle erwähnten Personen |
authority
Alle Personen mit einer Norm-ID einer bestimmten Norm-Datei (eingeschränkt ggf. durch type)
| Wert | Beschreibung |
| gnd | Gemeinsame Normdatei der Deutschen Nationalbiblitothek; standardmäßig gesetzt, sofern nicht anders angegeben |
| viaf | Virtual International Authority File |
Context Objects in span (COinS) & Zotero-API
Die Einträge der Bibliographie sind ebenfalls über APIs zugänglich. Zum
einen werden sie jeweils als maschinenlesbare ContextObjects in Spans![]() in die HTML-Seite der edition humboldt digital eingebettet. Dadurch
können sie direkt per Mausklick in gängige Literaturverwaltungssysteme
übernommen werden. Zum anderen ist die komplette Biographie als
öffentlich einsehbare Zotero-Gruppe auch über die Zotero-API
in die HTML-Seite der edition humboldt digital eingebettet. Dadurch
können sie direkt per Mausklick in gängige Literaturverwaltungssysteme
übernommen werden. Zum anderen ist die komplette Biographie als
öffentlich einsehbare Zotero-Gruppe auch über die Zotero-API![]() unter https://api.zotero.org/groups/667230/items
unter https://api.zotero.org/groups/667230/items![]() zugänglich.
zugänglich.
Versionierung, Permalinks und Zitierhinweise
Die in edition humboldt digital bereitgestellten Texte
und Daten werden versioniert vorgehalten, d.h. jede veröffentlichte Version
(i.d.R. eine pro Jahr) der Inhalte wird zum Abruf vorgehalten. Versioniert wird
dabei stets der gesamte, veröffentlichte Datenbestand. Dadurch bilden auch die
Registereinträge die Verknüpfungen der jeweiligen Version ab (vgl. z.B. den
Eintrag zu Georg Forster in Version 1![]() gegenüber
Version 9
gegenüber
Version 9![]() ).
Einen Überblick über die Veränderungen zwischen den Versionen der edition humboldt digital gibt die mit Version 8
eingeführte Versionsgeschichte
).
Einen Überblick über die Veränderungen zwischen den Versionen der edition humboldt digital gibt die mit Version 8
eingeführte Versionsgeschichte![]() . Dabei werden auch die Anzahl der edierten Seiten,
angelegten Chronologie- und Registereinträge sowie kodierten
Entitätenverknüpfungen ausgewertet und als Balkendiagramme visualisiert. Dadurch
soll auch die fortschreitende Arbeit an den edierten Texten dokumentiert werden.
. Dabei werden auch die Anzahl der edierten Seiten,
angelegten Chronologie- und Registereinträge sowie kodierten
Entitätenverknüpfungen ausgewertet und als Balkendiagramme visualisiert. Dadurch
soll auch die fortschreitende Arbeit an den edierten Texten dokumentiert werden.
64Alle Texte sind sowohl mit einem Zitierhinweis, als auch mit Permalinks versehen,
die auf die jeweilige Version referenzieren (z.B.: http://edition-humboldt.de/v1/H0002656![]() ; zur Zitier- und
Referenzierbarkeit bei digitalen Editionen vgl. Bleier 2021). Bei Bedarf kann dabei
bei edierten Texten auch auf das jeweilige Folium referenziert werden, indem
einfach die Folio-Angabe im Pfad ergänzt wird z.B. https://edition-humboldt.de/v9/H0002656/2v
; zur Zitier- und
Referenzierbarkeit bei digitalen Editionen vgl. Bleier 2021). Bei Bedarf kann dabei
bei edierten Texten auch auf das jeweilige Folium referenziert werden, indem
einfach die Folio-Angabe im Pfad ergänzt wird z.B. https://edition-humboldt.de/v9/H0002656/2v![]() . Forschungsbeiträge, die
aufgrund ihres „digital born“-Charakters nicht über Seitenzahlen verfügen,
können dagegen absatzweise zitiert werden. Dazu wird die Absatznummer (die stets
links oben nebem jeden Absatz angezeigt wird) als sog. Fragment-Identifier mit
einer # angehängt, z.B. https://edition-humboldt.de/v9/H0016432#3
. Forschungsbeiträge, die
aufgrund ihres „digital born“-Charakters nicht über Seitenzahlen verfügen,
können dagegen absatzweise zitiert werden. Dazu wird die Absatznummer (die stets
links oben nebem jeden Absatz angezeigt wird) als sog. Fragment-Identifier mit
einer # angehängt, z.B. https://edition-humboldt.de/v9/H0016432#3![]() . Von der Verwendung von
Digital Object Identifier (DOI) wurde abgesehen, da sie keinen wirklichen
Mehrwert bieten. Im Gegenteil: da ihre Registrierung kostenpflichtig ist, würden
sie erhebliche Kosten verursachen (es müssten ja schon für jede Seite der
edierten Texte in jeder Version DOIs erstellt werden, von den Registereinträgen
ganz zu schweigen) und neben den schon vorhandenen Permalinks eine weitere
Schicht von Links etablieren würde, die gepflegt werden müsste. Trotzdem müssten
alle Maßnahmen zur Langzeitverfügbarkeit der ehd auch bei Verwendung von DOIs
vorgenommen werden.[10] Der auf Zenodo veröffentlichte TEI-XML-Datensatz ist
allerdings mit einem DOI versehen.[10] Zur Problematik von
DOIs siehe auch Arnold und Müller
2017.
. Von der Verwendung von
Digital Object Identifier (DOI) wurde abgesehen, da sie keinen wirklichen
Mehrwert bieten. Im Gegenteil: da ihre Registrierung kostenpflichtig ist, würden
sie erhebliche Kosten verursachen (es müssten ja schon für jede Seite der
edierten Texte in jeder Version DOIs erstellt werden, von den Registereinträgen
ganz zu schweigen) und neben den schon vorhandenen Permalinks eine weitere
Schicht von Links etablieren würde, die gepflegt werden müsste. Trotzdem müssten
alle Maßnahmen zur Langzeitverfügbarkeit der ehd auch bei Verwendung von DOIs
vorgenommen werden.[10] Der auf Zenodo veröffentlichte TEI-XML-Datensatz ist
allerdings mit einem DOI versehen.[10] Zur Problematik von
DOIs siehe auch Arnold und Müller
2017.
Darüber hinaus sind die einzelnen Texte und Datensätze auch mit einer kanonischen
URL versehen, die stets auf die aktuellste Version weiterleitet. Dabei entfällt
einfach der Versionshinweis im Pfad, z.B. http://edition-humboldt.de/H0002656![]() . Neben den Texten und
Registereinträgen sind auch bestimmte Unterbereiche (Themenschwerpunkte und
verschiedene Briefwechsel), die sich – wie ein Band – eigentlich aus mehreren
Texten zusammensetzen, mit eigenen Zitierhinweisen inkl. kanonischen Links
versehen (z.B. https://edition-humboldt.de/X0000003
. Neben den Texten und
Registereinträgen sind auch bestimmte Unterbereiche (Themenschwerpunkte und
verschiedene Briefwechsel), die sich – wie ein Band – eigentlich aus mehreren
Texten zusammensetzen, mit eigenen Zitierhinweisen inkl. kanonischen Links
versehen (z.B. https://edition-humboldt.de/X0000003![]() ).
).
Durch die kanonischen und gleichförmigen URLs („H“ und eine siebenstellige Ziffer) ist es auch möglich geworden, dass die gedruckten Bände der edition humboldt print bei edierten Texten auf das digitale Pendant zurückverlinken.
Die Oberfläche an sich, d.h. die XQL-, XSLT- und JS-Skripte sowie CSS- und
sonstige Dateien, wird derzeit nicht öffentlich versioniert. Sie wird aber für
Entwicklungszwecke in einem Git versioniert und vorgehalten. Für die Zukunft ist
darüber hinaus angedacht, jede Version der digitalen Edition (als Oberfläche)
zusätzlich im Web-Archiv der
BBAW![]() abzulegen und dort vorzuhalten. Dabei wird die edition humboldt digital derzeit schon so technisch vorbereitet, dass
sie sich bestmöglichst archivieren lässt.
abzulegen und dort vorzuhalten. Dabei wird die edition humboldt digital derzeit schon so technisch vorbereitet, dass
sie sich bestmöglichst archivieren lässt.
Davon unabhängig werden zusätzlich die Daten dauerhaft auf Zenodo publiziert und archviert (siehe Abschnitt „Datenpublikation“).